Distributed bugs are often latent: a Troubleshoot Story
Abstract
OpenStack, as a nested distributed system(where some of the subsystems are distributed systems), to troubleshoot on it could be quite tricky, not to mention its interdependence with other distributed systems in real word.
We all share the feelings on how hard it is to solve a hidden issue in a distributed system as each call during a chain of invocation is unpredictable, the methods/ tools for sniffing/ tracking each part are either too hard, incapable, outside of control, or too expensive.
The trigger made me composing this blog is the article: Challenges with distributed systems from Jacob Gabrielson, where Jacob expounded how and why designing/ managing a request/response distributed system is challenging. I recommend to read it 😊.
The story in this blog is a troubleshoot case I solved in a customer staging network years ago, where OpenStack clusters were integrated with some other different (virtual) Network Function clusters.
Background
There were many OpenStack Clusters onsite, with different VNFs running on top of them.
Two months before I arrived the customer site, the alarm
[NTP Upstream Server Failure]was raised in one of the OpenStack Cluster.Every party involved on this issue had looked into it jointly and each of them claimed they are all good: no clue to move on, and after the whole site’s yearly power down and up activity, the issue was gone.
One week ago, after a control plane nodes reboot, this alarm was raised again on another OpenStack Cluster.
Reviewing everything to have the pattern of the issue:
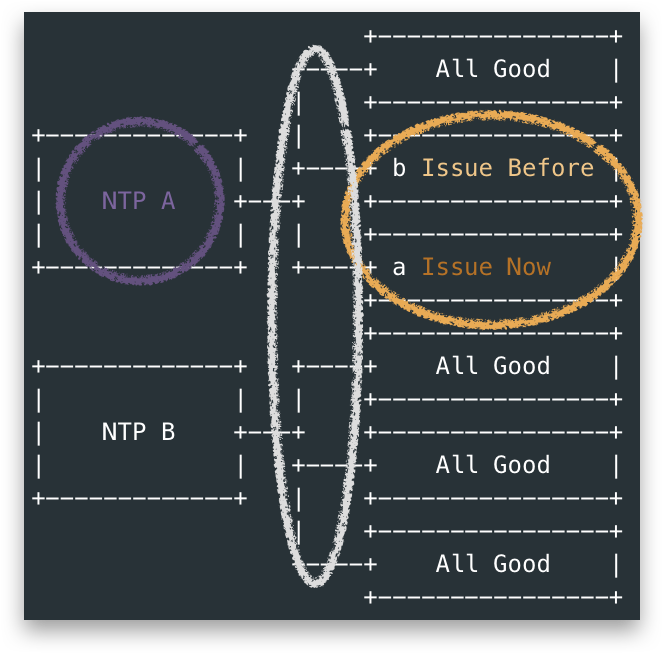
There were two types of servers acted as upstream NTP for Openstack Clusters. Let’s say NTP-A and NTP-B, they were actually not dedicated NTP servers but a more heavy network function(NF):
![]()
- NTP-A was the one associated with the issue OpenStack Clusters, which was a VNF running in Linux.
- NTP-B was a native NF in Solaris, to be repalced by NTP-A in future. #Customer has reasons to worry the issue more 😜.
The OpenStack side claimed they were good because they captured the NTP client packet sent to NTP-A and no response recieved.
The other side checked everything around NTP configuration, network etc. nothing abnormal was sorted out. Thus they had to blame the OpenStack side as there were other systems utilizing their NTP-A as upstream NTP, while no issues had encounterred.
Then both side suspected the packet was dropped somehow between NTP-A and OpenStack Cluster: the networking/ switches.
- The switch team observed nothing pointing to packet drop from the traffic .
- Even though there was chance they didn’t capture the drop on right time, why only OpenStack’s NTP request not responded?
- Was this issue happening in small frequency?