Project Resource Board: a scalable webapp with Flask socketio and Vue.js
关于
我在做一个叫做 resource board的 side project, 它是一个方便团队协作中使用共享资源的web app。
本文是我在写第一个发布版本之前持续更新的记录。
updated in
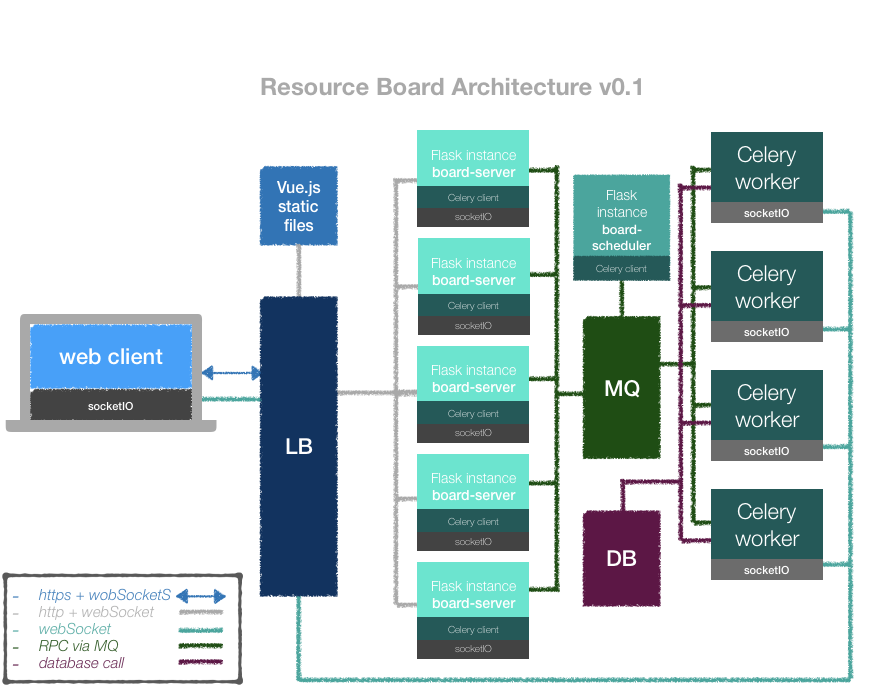
2019-April-6以单体架构先实现了可用的版本,部署在公司内网给项目使用上了,也公布一下代码:
https://github.com/wey-gu/resource-board
之后我会花时间迭代下去,不过现在课余时间在做一个机器学习调优的项目,这个优先级只能降低。
缘起
为什么开始
在云计算研发部门搬砖半年,一直做一些很小的feature开发,连着几个月早出晚归加上牺牲周末时间的赶进度让我内心很不平静。我需要做点什么,因为本质上我热爱的是 build things,做一个proper side project 的主意在脑子里转了好久了,我决定先做一个简单的东西出来。
这个东西就是一个 resource board 。
学到什么
resourece borard 是我起的名字,其实就是一份在线的表格、面板,本质上用 O365 / onedrive for business 完全可以实现类似的功效。不过我还是想造这样一个轮子,涉及一下产品开发的全生命周期的从无到有的创造、学习、实践:
- planning, prototyping
- architecture
- front end
- back end
- CI/ CD
- maintenance
- refactoring
- for test
- for scale
- tuning
User story of resource board
resource board 主要解决异地团队协作中对共享资源使用的问题,它是一个电子化的资源使用白板。
试想一下没有资源占用白板的时候,团队里的人共享10个虚拟化数据中心,我们简称 DC ,对于它的使用分几个场景:
- CI
- 被CI占用,没有再触发CI调用它的人不可以干预
- testing
- 被非独占式的人使用中,特定的人可以并行使用它,(理想情况下)不会干扰到彼此
- occupied
- 被人独占使用,不可与别人共享
- free
- 任何人可以使用它,或者挪作其他用途
这种情况下,使用它的A同学需要站起来告诉所有人,或者群发邮件,说我要用 DC123 独占调试一个代码,有人在用么? 10分钟后,在注意到没人回复的情况下,ta就在 DC123上开始做坏事 调试ta的代码了。然而刚从厕所回来的B同学,却发现ta的环境被破坏了,半天白忙活了😢。
如果这个资源共享的工作方式之中引入了记录资源占用情况的白板,A同学只需要看一下白板上空闲的DC,发现DC125 可以使用,他可以做到:
- 无需等待确认广播信息的回复立刻使用
DC125 - 不会破坏任何被占用的资源环境比如
DC123
看起来比较自然。
Planning
关键点
- 数字化白板应该是一个Wep App
- 它需要是实时的
- 支持面向连接的(server —> client)
- 可扩展,可扩容
- 后端
- 只做api
- 分布式,可scale up
- 前端
- single page client
- websocket
- 后端
简单原型
我用Balsamiq Mockups 简单做了一个原型:
- 用卡片表示每一个资源的信息
- 不同的section表示资源被使用的状态,或者分类
- 提供面向资源的历史查看页面
我没有花更多时间去画更详细的原型图,只是在画这个初始的版本的过程中引导我思考我初始的数据schema,前后端最开始要做的事情,一旦雏形确定下来,我就直接进入前后端的开发,在开发中直接实现业务逻辑的进化。
这里是我截取的原型图的demo动画 😁