Pokemon Club, a demo app with Nebula Graph
About
In the database world, there is one type of NoSQL DB called graph database, which is good at the query of traversing relationships between small entities, like:
- Find one person’s 5th-degree friend connections in LinkedIn
- Detect fraud, starting from one bank account number, connected to its account address, card owner’s social identity number, and recent bank activities, the all linked relationship graph can be queried in realtime and then checked towards certain fraud pattern
Today, I will create a minimal PoC to build one tiny App leveraging a graph database, Nebula Graph.
Nebula Graph is an open-source new graph DB built natively for globally distributed deployment in hyper-scale, with the help of raft consensus algorithm and architecture of shared-nothing, it’s like the Google Spanner or CRDB/TiDB in the graph DB world.
Pokemon Club
Photo from Michael Rivera 🇵🇭

Today, let’s build a new SNS for the Pokemon Trainers, the Pokemon Clubhouse ;)
Pokemon Club is targeting to connect all Pokemon Trainers for their meetup or grouping to fight in certain Pokemon Go Gym.
Like FB or Linkedin, we for sure have the User System with relational DB backed and users metadata of age, avatar, location, and Pokemons she owned, etc. Users as a trainer can create meetups and share posts in Pokemon Club and her friends can get the news feed and comment, join or chat to her.
Apart from the main features, we will only focus on one feature to help trainers explore new friends recommended by the App, based on the Pokemons this trainer owns.
Now we assume either in streaming/ real-time or the batch way, we had put trainer and pokemon relationship in our Nebula Graph DB, and then to create a humble API to get the recommended trainer friends:
1 | /v1/recommended_friends/<user> |
Then let’s start the hands-on part!
The Hands-on part!
Let’s do bottom-up from the Nebula Graph DB:
Deployment of Nebula Graph
Nebula Graph is released in shapes from source code tarball, [RPM/DEB package](RPM/DEB package), Docker containers, and docker-compose to helm chart or a k8s CRD/operator.
Here, we will start with the smallest footprint and the easiest way, the docker-compose fashion referring to https://github.com/vesoft-inc/nebula-docker-compose.
Here I spawned a preemptible(cheap, no SLA) VM from GCP for this ad-hoc purpose, with the spec of Intel CPU and 8GiB ram, in a Ubuntu 18.04 LTS image.
Also, I allowed TCP ports of 6996 and 7001 from the firewall setting associated with the VM.
Below is the deployment commands in this machine:
1 | sudo su -i |
Nebula Graph Schema and Mock Data Import
Graph Data Schema
Here we created the plainest schema with two types(tags) of vertices and two types of edges:
Vertices:
- trainer
- property:
- name
- …
- property:
- pokemon
- property:
- name
- …
- property:
- trainer
Edges:
- owns_pokemon
- source: trainer
- dest: pokemon
- is_friend_with
- source: trainer
- dest: trainer
- owns_pokemon
From the below image, it’s easier for us to understand the schema:
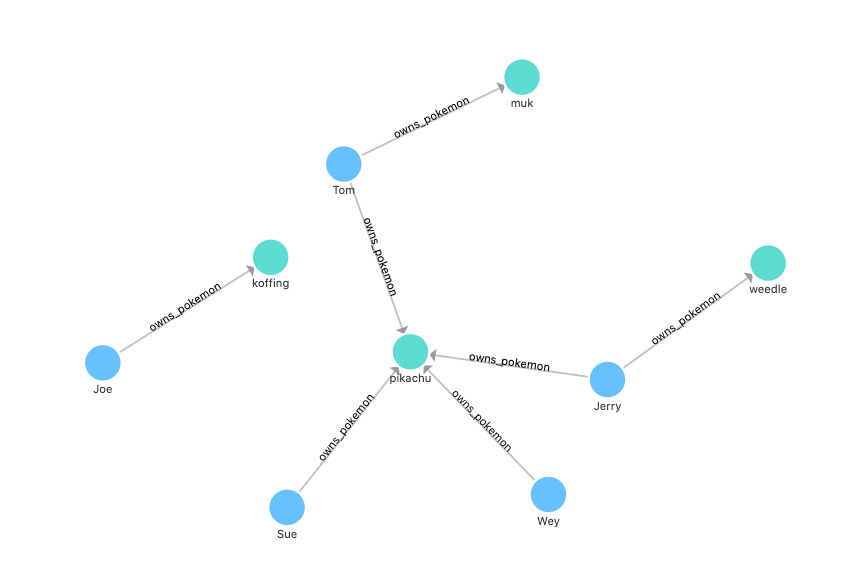
1 | CREATE SPACE pokemon_club (vid_type = FIXED_STRING(16)) |
Data Import
For hyper-scale data migration into Nebula Graph, there is a Spark utility named Nebula Exchange to generate RocksDB SST files to enable extremely high import efficiency.
For a small scale of data, the utility nebula-importer is enough, with which, we could define mapping rules in a yaml file and import CSV files.
Here we leverage a GUI utility in Nebula Studio as it comes with a guided process to define the mapping rule in the web console itself and call the underlying nebula-importer for us w/o composing the yaml file ;).
We have mocked data for importing as below:
- trainer–>pokemon
1 | Tom,pikachu |
- trainer –> trainer
1 | Tom,Jerry |
Please refer to the video demo on how this mapping could be done in Nebula Studio :).
Query the data from Nebula Graph
Cool! Now we have a distributed graph DB with some data schema defined and some Pokemon Trainers data is also there!
To simplify the PoC, we assume that the recommendation API will query in this logic:
- For a given trainer Tom, what are those trainers own the same Pokemons Tom owned?
I know it’s quite a silly logic though ;-), it’s just a minimal example here.
Nebula Graph comes with a SQL-like query language named nGQL, you can for sure refer to its doc here, and in the video, I showed you how to create a query with the help of the Explore GUI in Nebula Studio.
owns_pokemonis the edge- the query
OVERit means to goFROMits source end, which istrainertag - we
YIELDits dest end, which ispokemontag, aspokemon_id - then we used
|(pipe operator) to pipe the query result in next query starting from the secondGO $-stands for the piped result namespace and wo start from$-.pokemon_idnow- again we query
OVERsame edge with one extraREVERSELYkey word, yes! it means the other direction this time:FROMits dest end!
1 | GO FROM "Tom" OVER owns_pokemon YIELD owns_pokemon._dst as pokemon_id \ |
The API code handles Web Request and Invokes Nebula Graph
There are different client libs there and now we are using the Python one: https://github.com/vesoft-inc/nebula-python.
I created a simple Flask App with nebula2-python to call our Nebula Graph cluster, the main code logic is as below:
- it takes api query in format
/v1/recommended_friends/<user>and returns result in JSON.
1 |
|
After deployed it to Cloud Run and configured the Nebula Graph’s graphd endpoint in env of the cloud run instance, we will have an external URL to enable anyone in the word to query it, and it looks like this:
1 | $curl https://pokemon-club-v1-****-uw.a.run.app/v1/recommended_friends/Tom | jq |
Below are how I deployed it into GCP Cloud Run and I put all code in GitHub(https://github.com/wey-gu/pokemon_club) as well.
The Dockerfile
1 | # Use Python37 |
build and deploy container to Cloud Run
1 | export PROPJECT_ID=<GCP_PROJECT_ID> |
More Working In Progress
To Do:
- Video Demo(s)
- Adding
Fraud🚀Team Rocket hidden member detection API, like based on who owns Koffing - Front End Part
- Invoking Pokemon API
- catalog for human: https://pokemondb.net/pokedex/national#gen-1
- metadata fetching: https://pokeapi.co/
- image fetching: https://pokeres.bastionbot.org/images/pokemon/109.png #
109is Pokemon ID here.
- Invoking Pokemon API
More on Nebula Graph
Nebula Graph is already used by some Gaint Companies and its community is quite active, with the help of that, it grows fast and comes with some great utilities like an extremely fast batch importing tool.
Apart from the k8s native deliverable, also it started to provide a managed service Graph DBaaS, in the test phase though.
Hopefully I could create more contents on Nebula Graph later :), stay tuned!